






Challenges of Building Fraud Detection and Prevention Systems

Techniques to detect and prevent Frauds: Expert driven fraud detection and prevention technique represents a good starting point and complementary to other approach used. Alternatively, used techniques should be accurate, operationally efficient and cost efficient. All these qualities can be observed in statistically used credit score card or customer churn model. These solutions are data-based and an application of supervised learning. They are built upon the vast amount of data available and it takes 3 to 6 months to build a model. Once they are built, they can be checked for accuracy on monthly basis and can be calibrated if required. It keeps the cost in control. If critical variable used are maintained, its easy to do operationally compute fraud and non-fraud cases. It takes us towards the data driven solutions. To make these solutions usable for transactional processing such as credit card transaction decision making, they need to be automated. Rule engine integrated with data driven solution provides answers to it.
Although data driven solutions provide answer to the problem. But they are based on historical data and fraud pattern. Fraud is dynamic thing, fraudster change their way of doing frauds, as soon as they start getting caught. They experiment with fraud detection and prevention system and find a new way of doing fraud. So, fraud detection and prevention system need to evolve with time as fraudster find new ways of doing frauds. It takes us towards the unsupervised learning. Descriptive analytics is used to detect the possible anomaly or outlier in the system. Outlier techniques helps in detecting the new fraud pattern and catch the new way of doing the fraud.
In addition to supervised and unsupervised techniques, it makes sense to utilize the already available information. Fraudsters normally operate in groups, plan and execute those plans. So, it helps when social network analysis is performed to find the network of people committing frauds based on few critical variables. That’s where fraud ring is introduced, any customer part of a fraud ring is investigated thoroughly for suspicious fraud.
An effective fraud detection and prevention system uses the all the three techniques as complement to each other to detect and investigate frauds.
Cycle of Fraud detection system: Below diagram shows the cycle of fraud detection system (Source: Internet)

Fraud detection refers to applying the fraud model on new observations. Fraud investigation is carried out on the cases flagged fraud by the fraud detection system. Once fraud is confirmed then we check the accuracy of fraud model used. If fraud model is still good, then we don’t need to update the model. But if accuracy breach is violated then we need to re-train the model on historical data. New detected cases should be added to historical data as soon as possible to keep the system optimal. The model update depends on accuracy of current model, the rate at which new case are confirmed, time required for update and cost of updating the model.
Fraud Model creation process: Fraud model creation and detection process is described in the diagram below. (Source: Internet). Dataset variable are identified based on business problem. Those tables with such variables are identified and merged to create the final dataset. This data is cleaned to ensure the consistency of format across different variables. Outlier treatment and missing value is performed to further clean the data. Variable in data are then transformed to create new trend variables. Once data is ready after all these operations, it’s divided into training and test dataset. Model is trained on training dataset and validated on test dataset. After couple of iteration once model is finalized. This model is deployed in rule engine to process the coming stream of new data to make predictions.
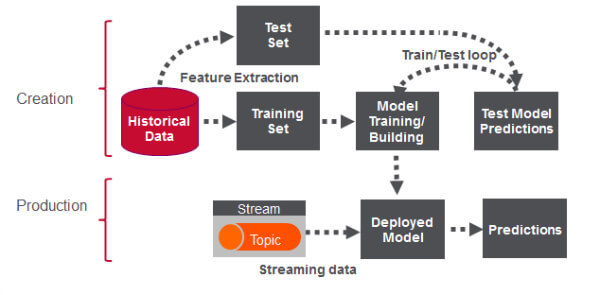
This most time-consuming part of this exercise is data cleaning, which take 70% of the time. Before deployment, each model is evaluated for model accuracy, interpretability, operationally efficiency, economic efficiency and regulatory compliance. Models, which allows to understand the underlying reason of fraud are called white box model. While the model, which doesn’t allow to understand the reason of fraud are called black box model. Depending upon the technique used, model could be white box or black box.
| Modelling technique | Solution type |
| Logistic regression | White box |
| Decision tree | White box |
| Random forest | Black box |
| Gradient boost method | White box |
| Neural network | Black box |
Briefly about the capability of fraud analyser: Fraud analyser implements both white box and black box supervised techniques to build the model, depending upon requirement appropriate technique is used. Fraud analyser allows to detect the fraud using historical data by building a model over it using an optimal modelling technique depending upon the situation, which helps to detect the fraud done using current techniques. It allows to use unsupervised technique to detect the outlier and anomaly in the system and help to detect new innovative ways of doing fraud. Social network detection technique such as fraud ring allows the potential fraud happening using fraud network. Fraud analyser comes with a data scientist in subscription to do all this for you at a fixed cost.