





Fraud Analyser
- Home
- Fraud Analyser
PROCESS OF FRAUD DETECTION AND PREVENTION
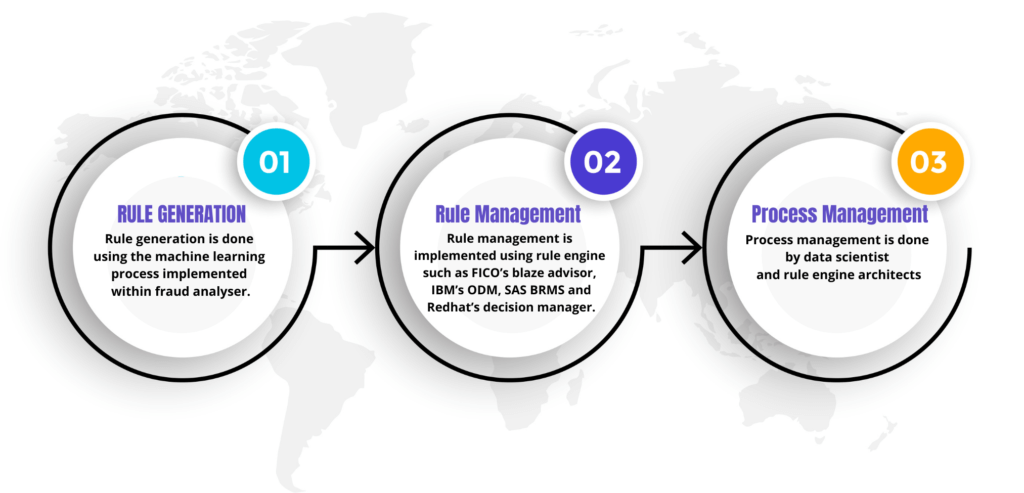
There are three layers of processes for fraud detection and prevention
-
Rule Generation
Rule generation is done using the machine learning process implemented within fraud analyser.
-
Rule Management
Rule management is implemented using rule engine such as FICO’s blaze advisor, IBM’s ODM, SAS BRMS and Redhat’s decision manager.
-
Process Management
Process management is done by data scientist and rule engine architects
RULE GENERATION USING
FRAUD ANALYSER
The machine learning layer connects the rule-detection and relevant modelling functions. It starts by generating the rules-based framework from the initial training dataset by using most relevant machine learning algorithms.
There had been solutions in the market but most of them are rule based solutions. These rules are implemented by the expert knowledge based on logical conclusions derived in history.

These rules are updated on yearly basis. So, there is good chance in one-year duration by acquiring the knowledge of the system and invent new techniques to do frauds. Incidentally, fraud happens, and it goes undetected. So, there is requirement of solutions that are updated dynamically every quarter based on rules detected from recent frauds.We have implemented the solutions based on machine learning techniques for few of our clients in Africa based on machine learning techniques. Rules are detected on monthly basis using statistical techniques. There are two kinds of rules i) based on past trends ii) based on current trends. The rules based on past trends are discovered by building a fraud score card on last 1 to 3 years historical data. The rules based on current trends are discovered using the anomaly detection techniques such as outlier detection.
To detect the past trends using historical data, we collect the historical data of close to last two years. We use the observation windows of one year and performance window of 6 months to 1 year depending upon when the fraud rate stabilizes. We derive lots of trend variables using the data in 1-year observation window. Then we build the behavioral score card using latest machine learning techniques such as random forest, neural network and gradient boost method. The performance parameter such as accuracy ratio and area under curve for score card is maximized. The performance parameter such as false positives and false negatives are also minimized.
Machine Learning techniques used include:
- Random forest
- Neural network
- Decision tree
- Logistic regression
To detect the current trends using current data, one of anomaly detection techniques such as fraud rings or outlier detection is used. Fraud rings describes the association between fraudsters and association between non fraudsters. If claim is found to be part of fraud network, it is thoroughly investigated. Outlier detection happens at claim level first. Once a claim is detected an outlier using un-supervised techniques such as k-means then it is investigated further based on key variable’s data to find the reason of being anomaly.
Both kind of rules based on past trends and current trends are applied to a new claim and results are reported to claim department. If a claim is reported to be fraud, then its investigation report is passed to fraud investigation team.
Both kinds of rules based on past trends and current trends are checked for consistency on monthly basis. PSI and CSI of key variables is compared in the latest data with data used for building the score card, if there is no significant difference then actual fraud rate is compared predicted fraud rate. If there is no significant change then we keep the same score card and rules are not updated. In case there is significant change in the both the parameters then we must build a new score card and rules are updated to keep the score card and rules relevant.
By using the latest machine learning techniques and keeping the process dynamic, we managed to achieve excellent results for our clients in Africa. We managed to detect 20% to 30% more fraud than rule-based management system. The machine learning techniques can complement the existing techniques based on expert knowledge, but they cannot replace the years of industry experience. Hence our solutions are a complement to existing solutions.
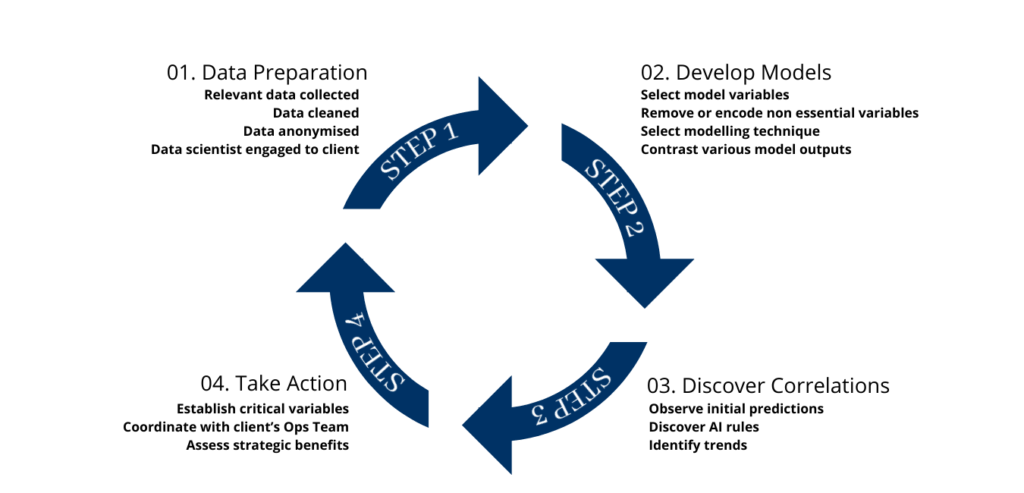
RULE GENERATION PROCESS
Generic example without any front end customisation, where annual subscribers are assigned a dedicated data scientist at no extra cost
01. Data Preparation
Relevant data collected
Data cleaned
Data anonymised
Data scientist engaged to client
02. Develop Models
Select model variables
Remove or encode non essential variables
Select modelling technique
Contrast various model outputs
03. Discover Correlations
Observe initial predictions
Discover AI rules
Identify trends
04. Take Action
Establish critical variables
Coordinate with client’s Ops Team
Assess strategic benefits
back to Step 01
RULES MANAGEMENT USING RULE ENGINE
Rules generated can be used within the context of detecting insurance fraud for (a) claim submissions or (b) policy applications. In cases that require immediate decisions integration of the rule engine with a front-end application is required.
Otherwise, rules can be exported into a range of formats including MS Excel or R.
We can add value across the board regarding rules-management by:
- Aiding development of rules according to your specifications
- Inserting rules into other products such as IBM ODM, Fico Blaze Advisor or some of the more cost optimal offerings on the market
- Aiding integration of rules engines with front-end applications, where scorecards are generated and decisions are outputted on the fly.
PROCESS MANAGEMENT BY DATA SCIENTIST AND RULE ENGINE ARCHITECT

Our team of data scientists, modellers, team leaders and product developers, has deep expertise in development ‘R’ and Python-based applications such as automation tools and modelling software. We understand the pain felt on the operational level and have taken steps to provide a solution that includes customisation, training and product support.
If you want support on higher level stuff like rule-optimisation, report generation or sector best practices, then we’ve got you covered there as well. There are no paid add-ons for getting the optimal level of output from our product, and we have done our best to reduce the usual stumbling blocks that may prevent this. Learn more about us at our team page. |
SECTOR COVERAGE
Fraud on part of the customer generally occurs while applying for the policy, or filing a claim. If the engagement model requires an instantaneous result, then this is possible by integrating with a front end application. |
Credit Cards
$ 27.85 Bn in 2018 and projected to exceed $ 35 Bn by 2023 – The Nilson Report
Health Insurance
Possibly the most challenging type of fraud to combat given the very wide range of issue
Home Insurance
Fraudulent claims up by 52% in the UK last year, with 31-40 year-plds leading activity - Cifas.
Life Insurance
Challenging conventinal segmentation and limits to improve resource allocation.
Vehicle insurance
Implementing measures to reduce temptation for customers to 'have a go'
Vehicle Financing
Implementing measures to reduce temptation for customers to 'have a go'
TYPES OF FRAUDS

Fraud in finance is defined as claiming money from banks or insurance company by deceiving them by wrong means. There are predominately following kinds of fraud, which is costing finance industry over 300 Billion Pounds worldwide.


CREDIT CARD FRAUD

In the case of credit card fraud, money is claimed from acquiring or merchant bank by customers by fraudulent means. In normal process, customer buys a product from merchant. Merchant claims money from his bank with proof of transactions, and merchant bank claims money from acquiring bank. As long customer is himself making a purchase and have enough balance, there is no fraud. But there could be cases when customer is buying from merchant and doesn’t have enough credits in his bank to pay for it. In this case, one of the bank merchants or acquiring bank loses the money. There could be cases, when credit card is stolen, and someone make a purchase and again one of the banks lose the money.
INSURANCE FRAUD

In the case of credit card fraud, money is claimed from acquiring or merchant bank by customers by fraudulent means. In normal process, customer buys a product from merchant. Merchant claims money from his bank with proof of transactions, and merchant bank claims money from acquiring bank. As long customer is himself making a purchase and have enough balance, there is no fraud. But there could be cases when customer is buying from merchant and doesn’t have enough credits in his bank to pay for it. In this case, one of the bank merchants or acquiring bank loses the money. There could be cases, when credit card is stolen, and someone make a purchase and again one of the banks lose the money.
In insurance sector, there are predominately two kinds of frauds – application fraud and claim fraud. In application fraud, someone makes an application on behalf of customer and doesn’t declare the actual condition such as real value of property, health condition of insured and condition of vehicle. Later, when property is damaged or vehicle is stolen or insured dies, more money is claimed than deserved.
The second kind of fraud is claim fraud. It is costing over 300 Billion pounds to the insurance industry. There are so many types of claims, but we are looking to focus on frauds in claim in home, health and automobile sector. The common example of fraud claim of vehicle could claiming a vehicle being damaged while it was sold to mechanic for dumping into parts, setting the vehicle on fire to claim insurance or dumping in cars somewhere like lake to claim insurance, where nobody could find it. The common example of home insurance claim fraud could be setting it on fire after taking all the expansive items out. The common example of health insurance claim fraud could be issuing policy to cancer patients, without disclosing the disease.
We use the historical data to generate the AI based fraud management rules. These fraud management rules are implemented in Rule Management system to give you dynamic score on monthly basis. Once the cases of frauds are found, they are further investigated by analyst to pinpoint the source of problem. We are using services of industry experts to provide the fraud score for each individual customer. If score is high and above a certain cut off, then it creates an alert for further investigations. We use both the quantitative and qualitative indicator to confirm the fraud score and issue the fraud alerts. Once the fraud alert is issued then an analyst will look into trends of data to pinpoint the suspected behaviour and this information is passed to investigation department.
AI rules are verified to check the consistency of fraud management data and realized fraud rate on monthly basis. The whole process is very dynamic and is managed by an analyst on monthly basis to ensure the accuracy.